Friday, 23 January, 2026
Version 1.11.4 of siegfried is now available. Get it here.
CHANGELOG v1.11.4 (2026-01-23)
- update go version to 1.24.0
- Roy speed-up by avoiding function calls in loops. Fixes #148. Implemented by Ross Spencer
- update PRONOM to v122
- update LOC to 2025-12-09
- update TIKA to v3.2.3
Saturday, 1 March, 2025
Version 1.11.2 of siegfried is now available. Get it here.
CHANGELOG v1.11.2 (2025-03-01)
- Filter introduced to improve Wikidata queries and
-harvestWikidataSigLen flag sets minimum length of Wikidata signatures. Implemented by Ross Spencer and Andy Jackson
-noprov flag introduced for Wikidata signatures. Implemented by Ross Spencerversion command for roy. Implemented by Ross Spencer- Wikidata definitions updated to 4.0.0. By Ross Spencer
- Logged error messages have more context. Implemented by Ross Spencer
- update PRONOM to v120
- update LOC to 2025-02-26
- update TIKA to v3.1.0
- Explicitly declared variable offsets are parsed e.g. fmt/1840. Implemented by Rijnder Wever
Friday, 28 June, 2024
Version 1.11.1 of siegfried is now available. Get it here.
CHANGELOG v1.11.1 (2024-06-28)
- WASM build. See pkg/wasm/README.md for more details. Feature sponsored by Archives New Zealand. Inspired by Andy Jackson
-sym flag enables following symbolic links to files during scanning. Requested by Max Moser- XDG_DATA_DIRS checked when determining siegfried home location. Requested by Michał Górny
- Windows 7 build on releases page (built with go 1.20). Requested by Aleksandr Sergeev
- update PRONOM to v118
- update LOC to 2024-06-14
- zips piped into STDIN are decompressed with
-z flag. Reported by Max Moser
- panics from OS calls in init functions. Reported by Jürgen Enge
Sunday, 17 December, 2023
Version 1.11.0 of siegfried is now available. Get it here.
CHANGELOG v1.11.0 (2023-12-17)
- glob-matching for container signatures; see digital-preservation/pronom#10
sf -update requires less updating of siegfried; see #231- default location for siegfried HOME now follows XDG Base Directory Specification; see #216. Implemented by Bernhard Hampel-Waffenthal
- siegfried prints version before erroring with failed signature load; requested by Ross Spencer
- update PRONOM to v116
- update LOC to 2023-12-14
- update tika-mimetypes to v3.0.0-BETA
- update freedesktop.org to v2.4
- panic on malformed zip file during container matching; reported by James Mooney
Tuesday, 25 April, 2023
Version 1.10.1 of siegfried is now available. Get it here.
CHANGELOG v1.10.1 (2023-04-24)
- glob expansion now only on Windows & when no explicit path match. Implemented by Bernhard Hampel-Waffenthal
- compression algorithm for debian packages changed back to xz. Implemented by Paul Millar
-multi droid setting returned empty results when priority lists contained self-references. See #218- CGO disabled for debian package and linux binaries. See #219
Saturday, 25 March, 2023
Version 1.10.0 of siegfried is now available. Get it here.
The major changes in this release are the inclusion of a format classification field in results, a “droid” multi setting for roy, and improvements to the multi-sequence matching algorithm.
A new “class” field now appears in results (for the YAML, JSON and CSV outputs). It contains values from the format classification field in the PRONOM database which groups formats into categories such as “audio” and “database”. You can also omit the field when building a signature file with roy build -noclass. For the background to this change, see the discussion page.
DROID multi setting for roy build command
Roy’s multi flag has a new “droid” mode: roy build -multi droid.
This mode aims to more closely match DROID results by applying priority relationships after, rather than during, matching. This setting is more likely to show hybrid files than the default. For example, assume there is a file that is both a valid PDF and valid HTML document: in its default mode, siegfried, once it had positively matched either of those formats, would ignore the other because there is no priority relationship between them (e.g. having matched a PDF it will only consider more specific types of PDF). With the “droid” multi setting, both results would be returned as equally valid. For more information on this change see this issue.
Improvements to the multi-sequence matching algorithm
Siegfried uses a modified form of the Aho Corasick multiple-string matching algorithm for byte matching. This release includes a new dynamic version of the algorithm that pauses matching after all strings with maxium offsets have been tested and resumes matching with only the subset of strings that might still result in positive matches. By narrowing the search space, this improves performace for wildcard searches. This change has modestly increased performance for most of the benchmarks and creates scope for further optimizations in future releases.
CHANGELOG v1.10.0 (2023-03-25)
- format classification included as “class” field in PRONOM results. Requested by Robin François. Implemented by Ross Spencer
-noclass flag added to roy build command. Use this flag to build signatures that omit the new “class” field from results.- glob paths can be used in place of file or directory paths for identification (e.g.
sf *.jpg). Implemented by Ross Spencer
-multi droid setting for roy build command. Applies priorities after rather than during identificaiton for more DROID-like results. Reported by David Clipsham/update command for server mode. Requested by Luis Faria- new algorithm for dynamic multi-sequence matching for improved wildcard performance
- update PRONOM to v111
- update LOC to 2023-01-27
- update tika-mimetypes to v2.7.0
- archivematica extensions built into wikidata signatures. Reported by Ross Spencer
- trailing slash for folder paths in URI field in droid output. Reported by Philipp Wittwer
- crash when using
sf -replay with droid output
Sunday, 6 November, 2022
Version 1.9.6 of siegfried is now available. Get it here.
CHANGELOG v1.9.6 (2022-11-06)
Tuesday, 13 September, 2022
Version 1.9.5 of siegfried is now available. Get it here.
CHANGELOG v1.9.5 (2022-09-12)
roy inspect now takes a -droid flag to allow easier inspection of old or custom DROID files- github action to update siegfried docker deployment [https://github.com/keeps/siegfried-docker]. Implemented by Keep Solutions
- update PRONOM to v108
- update tika-mimetype signatures to v1.4.1
- update LOC signatures to 2022-09-01
- incorrect encoding of YAML strings containing line endings; #202.
- parse signatures with offsets and offsets in patterns e.g. fmt/1741; #203
Monday, 18 July, 2022
Version 1.9.4 of siegfried is now available. Get it here.
CHANGELOG v1.9.4 (2022-07-18)
- new pkg/static and static builds. This allows direct use of sf API and self-contained binaries without needing separate signature files.
- update PRONOM to v106
- inconsistent output for roy inspect priorities. Reported by Dave Clipsham
Monday, 23 May, 2022
Version 1.9.3 of siegfried is now available. Get it here.
CHANGELOG v1.9.3 (2022-05-23)
- JS/WASM build support contributed by Andy Jackson
- wikidata signature added to
-update. Contributed by Ross Spencer
-nopronom flag added to roy inspect subcommand. Contributed by Ross Spencer- update PRONOM to v104
- update LOC signatures to 2022-05-09
- update Wikidata to 2022-05-20
- update tika-mimetypes signatures to v2.4.0
- update freedesktop.org signatures to v2.2
- invalid JSON output for fmt/1472 due to tab in MIME field. Reported by Robert Schultz
- panic on corrupt Zip containers. Reported by A. Diamond
Monday, 7 February, 2022
Version 1.9.2 of siegfried is now available. Get it here.
CHANGELOG v1.9.2 (2022-02-07)
- Wikidata definition file specification has been updated and now includes endpoint (users will need to harvest Wikidata again)
- Custom Wikibase endpoint can now be specified for harvesting when paired with a custom SPARQL query and property mappings
- Wikidata identifier includes permalinks in results
- Wikidata revision history visible using
roy inspect
- roy inspect returns format ID with name
- update PRONOM to v100
- update LOC signatures to 2022-02-01
- update tika-mimetypes signatures to v2.1
- update freedesktop.org signatures to v2.2.1
- parse issues for container files where zero indexing used for Position. Spotted by Ross Spencer
- sf -droid output can’t be read by sf (e.g. for comparing results). Reported by ostnatalie
- panic when running in server mode due to race condition. Reported by Miguel Guimarães
- panic when reading malformed MSCFB files. Reported by Greg Lepore
- unescaped control characters in JSON output. Reported by Sebastian Lange
- zip file names with null terminated strings prevent ID of Serif formats. Reported by Tyler Thorsted
Tuesday, 22 September, 2020
Version 1.9.0 of siegfried is now available. Get it here.
This release includes a new Wikidata identifier, implemented by Ross Spencer.
CHANGELOG v1.9.0 (2020-09-22)
- a new Wikidata identifier, harvesting information from the Wikidata Query Service. Implemented by Ross Spencer.
- select which archive types (zip, tar, gzip, warc, or arc) are unpacked using the -zs flag (sf -zs tar,zip). Implemented by Ross Spencer.
- update LOC signatures to 2020-09-21
- update tika-mimetypes signatures to v1.24
- update freedesktop.org signatures to v2.0
- incorrect basis for some signatures with multiple patterns. Reported and fixed by Ross Spencer.
Wednesday, 22 January, 2020
Version 1.8.0 of siegfried is now available. Get it here.
This release includes changes in the byte matcher to improve performance, especially when scanning MP3s (fmt/134).
CHANGELOG v1.8.0 (2020-01-22)
- utc flag returns file modified dates in UTC e.g.
sf -utc FILE | DIR. Requested by Dragan Espenschied
- new cost and repetition flags to control segmentation when building signatures
- update PRONOM to v96
- update LOC signatures to 2019-12-18
- update tika-mimetypes signatures to v1.23
- update freedesktop.org signatures to v1.15
- XML namespaces detected by prefix on root tag, as well as default namespace (for mime-info spec)
- panic when scanning certain MS-CFB files. Reported separately by Mike Shallcross and Euan Cochrane
- file with many FF xx sequences grinds to a halt. Reported by Andy Foster
Sunday, 18 August, 2019
Version 1.7.13 of siegfried is now available. Get it here.
This minor release fixes a in the namematcher that caused filenames containing “?” to be treated as URLs. It also adds the ability to scan directories using the sf -f command.
Updates to the LOC FDD and tika-mimetypes signature files.
Change Log v1.7.13 (2019-08-18)
Added:
- the
-f flag now scans directories, as well as files. Requested by Harry Moss
Changed:
- update LOC signatures to 2019-06-16
- update tika-mimetypes signatures to v1.22
Fixed:
- filenames with “?” were parsed as URLs; reported by workflowsguy
Saturday, 15 June, 2019
Version 1.7.12 of siegfried is now available. Get it here.
This minor release fixes a bug that caused .docx files with .doc extensions to panic and a bug with mime-info signatures.
Updates to the PRONOM (v95), LOC FDD and tika-mimetypes signature files.
Change Log v1.7.12 (2019-06-15)
Changed:
- update PRONOM to v95
- update LOC signatures to 2019-05-20
- update tika-mimetypes signatures to v1.21
Fixed:
- .docx files with .doc extensions panic due to bug in division of hints in container matcher. Thanks to Jean-Séverin Lair for reporting and sharing samples and to VAIarchief for additional report with example.
- mime-info signatures panic on some files due to duplicate entries in the freedesktop and tika signature files; spotted during an attempt at pair coding with Ross Spencer… thanks Ross and sorry for hogging the laptop! #125
Saturday, 16 February, 2019
Version 1.7.11 of siegfried is now available. Get it here.
This minor release fixes the debian package and allows the container matcher to identify directory names (for SIARD matching). Updates to the LOC FDD and tika-mimetypes signature files.
Change Log v1.7.11 (2019-02-16)
Changed:
- update LOC signatures to 2019-01-06
- update tika-mimetypes signatures to v1.20
Fixed:
- container matching can now match against directory names. Thanks Ross Spencer for reporting and for the sample SIARD signature file. Thanks Dave Clipsham, Martin Hoppenheit and Phillip Tommerholt for contributions on the ticket.
- fixes to travis.yml for auto-deploy of debian release; #124
Wednesday, 19 September, 2018
Version 1.7.10 of siegfried is now available. Get it here.
This minor release fixes a regression in the LOC identifier introduced in 1.7.9 and updates to PRONOM v94.
Changelog v1.7.10 (2018-09-19)
Added:
- print configuration defaults with
sf -version
Changed:
Fixed:
- LOC identifier fixed after regression in v1.7.9
- remove skeleton-suite files triggering malware warnings by adding to .gitignore; reported by Dave Rice
- release built with Go version 11, which includes a fix for a CIFS error that caused files to be skipped during file walk; reported by Maarten Savels
Thursday, 30 August, 2018
Version 1.7.9 of siegfried is now available. Get it here.
According to the develop benchmarks, this release is slightly more accurate than v1.7.8, with only a marginal impact on performance.
The highlights of this release are a new system for saving configurations for the sf tool, changes to the matching algorithm to improve accuracy, and simplifications to the basis field.
Save and load frequently used configurations
The new -setconf flag allows you to save frequently used configurations for the sf tool. I implemented this to make it possible to set a default -multi value (and not require users to type e.g. sf -multi 32 every time they run siegfried), but you can use -setconf to save any frequently used flags. To save your preferred flags as defaults just type your preferred siegfried command, ommitting the file/directory argument and including -setconf.
For example, the following command records preferences for logging, output, hashing and -multi:
sf -setconf -csv -hash md5 -multi 32 -log time,error
You can then just type sf DIR to run siegfried with those preferred settings. Configurations are stackable with additional flags used while running siegfried. For example, if you type sf -json DIR after setting the above configuration, you’ll get JSON instead of CSV output for that session, but all those other preferences will be applied.
The -conf NAME flag allows you to save and load named configuration files. These configurations are saved to the path specified by the flag, rather than to the default configuration file (a sf.conf file in your siegfried home directory). Named configurations might be useful if you have a few different ways of invoking siegfried. For example, you might want to save a server configuration:
sf -setconf -hash sha1 -z -serve localhost:5138 -sig deluxe.sig -conf server.conf
You can then load that configuration by just typing sf -conf server.conf.
Changes to the matching algorithm
If you review the develop benchmarks, you’ll see that there are some small differences in the results returned for v1.7.9 as compared with v1.7.8. For example, in the Govdocs corpus, a number of PDF files had been identified as fmt/134 (MPEG) previously, but are now correctly identified as various forms of PDF. This improvement in accuracy follows some changes I’ve implemented to resolve this issue.
The problem boiled down to how siegfried uses PRONOM’s file format priority information. One of siegfried’s optimisations (and a reason it gives fairly good performance without requiring users to set limits on bytes scanned) is that it applies format priorities in real-time. For example, if, during scanning, a match comes in for PDF then siegfried will keep scanning to see if the file is a PDF/A (or other more specific type of PDF) but it won’t wait to see if the file is an MPEG or anything else unrelated to that initial match. Think of all the formats as a big tree: once siegfried starts climbing in a particular direction, it will only find results higher up that branch. But what if that initial match is misleading? Like those Govdocs PDFs where a noisy MPEG signature matched first?
The changes I’ve made to the matching algorithm for v1.7.9 retain siegfried’s real-time application of format priorities but with a tweak that allows siegfried to “jump” between branches in that format tree. The way this works is that, when each of the matchers runs (matchers are different stages in the scanning engine - i.e. the file name matcher, container matcher, byte matcher, text matcher etc.), “hints” are supplied based on information gleaned from previous matchers. These “hints” are then weighed alongside format priorities when siegfried decides what to do with format hits. For example, in the case of the Govdocs PDFs, the byte matcher receives a hint from the file name matcher that the file might be in the PDF family (because of the .pdf extension) and that hint causes the matcher to keep an open mind to the possibility that the file might well be a PDF even after that positive MPEG match has been found.
There is a small cost in speed for this change to the matching algorithm (because there is now this new factor that will cause siegfried to delay in returning a positive match early) but my benchmarks show that the slowdown is only very modest.
Please note: these format prioritisation rules only apply to siegfried in its default mode. The roy tool gives you fine-grained control over how format priorities are used during matching (i.e. you can elect to scan more slowly and get more exhaustive results returned). Try the roy build -multi positive, roy build -multi comprehensive and roy build -multi exhaustive commands described here to see how you can fine tune your results.
Simpler basis field
There is a small change in the information returned in the basis field for v1.7.9.
When reporting byte matches, siegfried returns the location (offset from the beginning of the file) and length (in bytes) of matches as pairs e.g. [10 150], which means a match at offset 10 for 150 bytes. For signatures with multiple segments (e.g. a beginning of file segment and an end of file segment), previous versions of siegfried reported a basis which was a list, of lists, of offset/length pairs. For example, you might get a basis like [[[10 150]][[25000 20]]]. The reason siegfried returned lists of lists rather than just simple lists of offset/length pairs was to account for the fact that sometimes particular segments of a signature would match at multiple points in the file. E.g. [[[10 150][30 200]][[25000 20]]] would indicate that that first segment had matched twice at different offsets and with different lengths.
The problem with this approach was that, for very noisy signatures (which generate a lot of segment hits), you could sometimes get very verbose basis fields in your results. In one reported case there was 3MB of data in one of these fields! For this reason, the basis field has been simplified in v1.7.9 and now just reports the first valid set of matching segments i.e. a list of offset/length pairs like [[10 150][25000 20]]. This means fewer square brackets and no more exploding basis fields!
Other changes
There are some other small bug fixes and tweaks in this release, as well as updates for signature files. Here’s the full changelog:
Changelog v1.7.9 (2018-08-31)
Added:
- save defaults in a configuration file: use the -setconf flag to record any other flags used into a config file. These defaults will be loaded each time you run sf. E.g.
sf -multi 16 -setconf then sf DIR (loads the new multi default)
- use
-conf filename to save or load from a named config file. E.g. sf -multi 16 -serve :5138 -conf srv.conf -setconf and then sf -conf srv.conf
- added
-yaml flag so, if you set json/csv in default config :(, you can override with YAML instead. Choose the YAML!
Changed:
- the
roy compare -join options that join on filepath now work better when comparing results with mixed windows and unix paths
- exported decompress package to give more functionality for users of the golang API; requested by Byron Ruth
- update LOC signatures to 2018-06-14
- update freedesktop.org signatures to v1.10
- update tika-mimetype signatures to v1.18
Fixed:
- misidentifications of some files e.g. ODF presentation due to sf quitting early on strong matches. Have adjusted this algorithm to make sf wait longer if there is evidence (e.g. from filename) that the file might be something else. Reported by Jean-Séverin Lair
- read and other file errors caused sf to hang; reports by Greg Lepore and Andy Foster; fix contributed by Ross Spencer
- bug reading streams where EOF returned for reads exactly adjacent the end of file
- bug in mscfb library (race condition for concurrent access to a global variable)
- some matches result in extremely verbose basis fields; reported by Nick Krabbenhoeft. Partly fixed: basis field now reports a single basis for a match but work remains to speed up matching for these cases.
Monday, 30 July, 2018
The next siegfried release will be out shortly. I have been busy making changes to address two thorny issues: verbose basis and missing results. I have some fixes in place but, when doing large scale testing against big sets of files, I noticed some performance and quality regressions. You can see these regressions on the new develop benchmarks page. There’s also a new benchmarks page to measure siegfried against comparable file format identification tools (at this stage just DROID). This post is the story of how these two pages came into being.
Benchmarking pain
Up until this point I had always done large scale testing manually and it was a fiddly and annoying process: I would have to locate test corpora on whichever machine I’d last run a benchmark on and and copy to my current laptop; run the tests; do the comparison; interpret the results; look up how to do golang profiling again because I had forgot; run the profiler and check those results; etc. After going through all these steps, if I made changes to address issues, I’d have to repeat it all again in order to verify I’d fixed the issues. Obviously none of these results had much shelf life, as they depended on the vagaries of the machine I was running them on, how I had configured everything, and would be invalidated each time there was a new software or PRONOM release. I was also left with the uneasy feeling that I should be doing this kind of large scale testing much more regularly. Wouldn’t it be nice to have some kind of continuous benchmarking process, just like the other automated tests and deployment workflows I run using Travis CI and appveyor? And down that rabbit hole I went for the last few months…
The solution
Today, whenever I push code changes to siegfried’s develop branch, or tag a new release on the master branch, the following happens:
- siegfried’s Travis CI script runs a little program called provisioner
- provisioner buys a machine for an hour or two from packet.net, feeding the new machine a cloud init script that runs a series of install tasks (like downloading and installing siegfried)
- the cloud init script concludes by starting another small program, runner, as a systemd service
- runner downloads a list of jobs from the itforarchivists.com website (either the develop jobs or the benchmark jobs) and executes them
- one of the early jobs is to use rclone to copy the test corpora over to the test machine from backblaze.com
- after running the jobs (and timing their duration), runner posts results back to the itforachivists.com website where they are stored and displayed on the develop and benchmarks pages.
Benefits of this approach are:
- it is completely transparent. Obviously as one of the tool makers there is potential for me to show some bias. But you can see exactly what machine has run the benchmark (packet.net sells “baremetal” servers so you get a clear picture of the hardware used), what software has been installed and how it has been configured, and exactly what tasks have been run.
- it is cheap to run: Travis CI is free for open source projects, backblaze is super cheap, backblaze has partnered with packet.net for free data transport between their data centres, and the packet.net servers are competitively priced (particularly when you buy from the spot market)
- it is routine. For me, this is the most important thing. I no longer have to go through benchmark pain and I can view the real world impacts of any changes I make to siegfried’s code immediately after committing changes to github.
Some reflections on the results
DROID has got really fast recently! Kudos to the team at the National Archives for continuing to invest in the Aston Martin of format identification tools :). I’m particularly impressed by the DROID “no limit” (a -1 max bytes to scan setting in your DROID properties) results and wonder if it might make sense for future DROID releases to make that the default setting.
In order to make the most of SSD disks, you really need to use a -multi setting with sf to obtain good speeds. I’m making this easier in the next release of siegfried by introducting a config file where you can store your preferred settings (and not type them in each time you invoke the tool).
If you really care about speed, you can use roy to build signature files with built in “max bytes” limits. These test runs came out fastest in all categories. But this will impact the quality of your results.
Siegfried is a sprinter and wins on small corpora. DROID runs marathons and wins (in the no limit category) for the biggest corpus. This is possibly because of JVM start-up costs?
Speed isn’t the only thing that matters. You also need to assess the quality of results and choose a tool that has the right affordances (e.g. do your staff prefer a GUI? What kind of reporting will you need? etc.). But speed is important, particularly for non-ingest workflows (e.g. consider re-scanning your repository each time there is a PRONOM update).
The tools differ in their outputs. This is because of differences in their matching engines (e.g. siegfried includes a text identifier), differences in their default settings (particularly that max byte setting), and differences in the way they choose to report results (e.g. if more than one result is returned just based on extension matches, then siegfried will return UNKNOWN with a descriptive warning indicating those possibilies; DROID and fido, on the other hand, will report multiple results).
Where’s fido? I had fido in early benchmarks but removed it because the files within the test corpora I’ve used cause fido to come to a grinding halt for some reason. I need to inspect the error messages and follow up. I hope to get fido back onto the scoreboard shortly!
I need more corpora. The corpora I’ve used reflect some use cases (e.g. scanning typical office type documents) but don’t represent others (e.g. scanning large AV collections). Big audio and video files have caused problems for siegfried in the past and it would be great to include them in regular testing.
Saturday, 2 December, 2017
Version 1.7.8 of siegfried is now available. Get it here.
This minor release updates the PRONOM signatures to v93 and the LOC signatures to 2017-09-28.
As the only changes in this release are to signature files, you can just use sf -update if you’ve installed siegfried manually. This minor release is just for the convenience of users who have installed sf with package managers (i.e. debian or homebrew).
Thursday, 30 November, 2017
Version 1.7.7 of siegfried is now available. Happy #IDPD17!
Get it here.
This minor release fixes bugs in the roy inspect command and in sf’s handling of large container files.
A new sets file is included in this release, ‘pronom-extensions.json’, which creates sets for all extensions defined in PRONOM. You can use these new sets when building signatures e.g. roy build -limit @.tiff or when logging formats e.g. sf -log @.doc DIR.
The other addition in this release is the inclusion of version metadata for MIME-info signature files (e.g. freedesktop.org or tika MIME-types). You can define version metadata for MIME-info signature files by editing the MIME-info.json file in your /data directory.
Thanks to Terry Jolliffe and Ross Spencer for their bug reports.
See the CHANGELOG for full details on this release.
Wednesday, 4 October, 2017
Version 1.7.6 of siegfried is now available. Get it here.
This is a minor release that incorporates the latest PRONOM update (v92), introduces a “continue on error” flag (sf -coe) to force sf to keep going when it hits fatal file errors in directory walks, and restricts file scanning to regular files (in previous versions symlinks, devices, sockets etc. were scanned which caused fatal errors for some users).
Thanks to Henk Vanstappen for the bug report that prompted this release.
Thursday, 14 September, 2017
In my recent updates to this site I’ve added a new “Chart your results” tool on the siegfried page (in the right hand panel under “Try Siegfried”). This tool produces single page reports like this: /siegfried/results/ea1zaj.
Before covering this tool in detail let’s recap some of the existing ways you can already analyse your results.
Other ways of charting and analysing your results
Command-line charting
I appreciate that not everyone is a command-line junkie, but the way I inspect results is just to use sf’s -log flag. If you do sf -log chart (or -log c) you can make simple format charts:
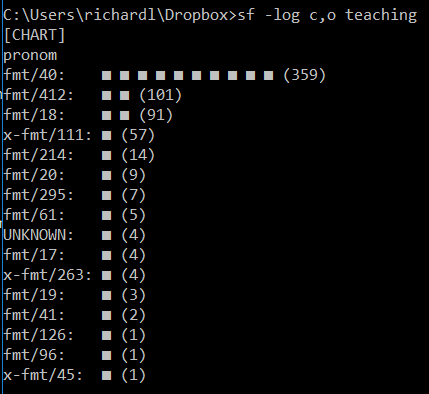
(In these examples I add “o” to my log options to direct logging output to STDOUT… otherwise you’ll see it in STDERR).
A chart can be a starting point for deeper analysis e.g. inspecting lists of files of a particular format:

You can also inspect lists of unknowns with -log u and warnings with -log w.
Rather than re-run the format identification job with every step, you can pair these commands with the -replay flag to run them against a pre-generated results file instead. I cover this workflow in detail in the siegfried wiki.
It would be remiss of me not to mention the two great standalone tools that Ross Spencer and Tim Walsh have written for analysing your results: DROID-SF sqlite analysis and Brunnhilde.
These tools both do a lot more than simple chart generation. E.g. DROID-SF can create a “Rogues Gallery” of all your problematic files. Brunnhilde has a GUI, does virus scanning, and can also run bulk_extractor against your files. I’d definitely encourage you to check both of these tools out!
Chart your results
If your needs are a little bit simpler, and you just want a chart, then my new “Chart your results” tool might be a good fit.
To try this tool, go to the siegfried page and upload a results file in the “Chart my results” form in the right-hand panel.
Let’s run through some of its features:
- it can handle siegfried, DROID and fido results files
- it gives you a single page, interactive report
- pie charts for format IDs and MIME-types
- highlights unknowns, errors, warnings, multiple IDs and duplicates (if you have checksums)
- you can drill-down on all of those features and formats to generate lists that you can export as CSV or to your clipboard
- supports multiple identifiers (a siegfried feature): each identifier is a separate single page report.
Probably the distinguishing feature of this tool is that you can easily share your analysis with colleagues, or with the digital preservation community broadly, by “publishing” your results. This gives you a permanent URL (like https://www.itforarchivists.com/siegfried/results/ea1zaj) and stores your results on the site. Prior to publication you can opt to “redact” your filenames if they contain sensitive information. I’ve added a privacy section to this site to address some of the privacy questions raised by this feature in a little more detail.
That’s it, please use it, and if you like it tweet your results!
Sunday, 13 August, 2017
Version 1.7.5 of siegfried is now available. Get it here.
The headline feature of this release is new functionality for the sf -update command requested by Ross Spencer. You can now use the -update flag to download or update non-PRONOM signatures with a choice of LOC FDD, two flavours of MIMEInfo (Apache Tika’s MIMEInfo and freedesktop.org), and archivematica (latest PRONOM + archivematica extensions) signatures. There are two combo options as well: PRONOM/Tika/LOC and the Ross Spencer “deluxe” (PRONOM/Tika/freedesktop.org/LOC).
PRONOM remains the default, so if you just do sf -update it will work as before.
To go non-PRONOM, include one of “loc”, “tika”, “freedesktop”, “pronom-tika-loc”, “deluxe” or “archivematica” as an argument after the flags e.g. sf -update freedesktop. This command will overwrite ‘default.sig’ (the default signature file that sf loads).
You can preserve your default signature file by providing an alternative -sig target: e.g. sf -sig notdefault.sig -update loc. If you use one of the signature options as a filename (with or without a .sig extension), you can omit the signature argument i.e. sf -update -sig loc.sig is equivalent to sf -sig loc.sig -update loc.
Other changes
sf -update now does SHA-256 hash verification of updates and communication with the update server is via HTTPS- update PRONOM signatures to v91
- fixes to config package where global variables are polluted with subsquent calls to the Add(Identifier) function
- fix to reader package where panic triggered by illegal slice access in some cases.
Saturday, 12 August, 2017
So I’ve updated this site. Apologies to those who liked the old look, which used the retro-Windows BOOTSTRA.386 theme. I liked it too. But it didn’t have great readability. The new CSS is basic, but it is super lightweight and I can tinker with it. I’m using Yahoo’s Pure CSS framework.
Under the hood, I’ve simplified the site a bit too. It used to be a monolithic golang app, served on appengine, but now most of the static content is generated by Hugo. The golang app parts now mostly just power a few small webservices (the update server, the try siegfried service, the sets tool, and the new chart tool). You can explore most of these services on the siegfried page.
The site’s code is up on github.

